· Woohyun Kim · Graphics · 14 min read
Mali GPU 추상 머신 1부 - 프레임 파이프라이닝
Mali GPU의 CPU-GPU 렌더링 파이프라인을 한국어로 정리한 번역 및 해설입니다.
목차
The Mali GPU - An Abstract Machine, Part 1 - Frame Pipelining The Mali GPU - An Abstract Machine, Part 2 - Tile based rendering
GLES API를 통해 렌더링 작업을 수행하는 대부분의 모바일 애플리케이션 개발에서는, 그래픽 작업의 로드에 대한 최적화가 필수적인 요소로 꼽힌다. 동료인 Michael McGeaghsms는 구글 넥서스10(Mali-T604)에서 GPU 프로파일링과 그래픽 애플리케이션의 최적화를 위해 DS-5 Streamline의 활용 가이드 [http://community.arm.com/docs/DOC-8055] 를 포스팅 하였다. Streamline은 높은 해상도를 가진 전체 시스템 동작의 데이터들을 쉽게 볼 수 있도록 제공하고 있으며, 따라서 이러한 데이터들을 분석하여 문제점을 찾아내고 수정할 수 있는 능력이 엔지니어에게 필요하다.
그래픽 최적화에 관해 처음으로 접하는 개발자에게는 초기 학습에 대한 진입 장벽이 다소 있을거라 생각하지만, 이 블로그에서 Mali GPU를 통해 최적화하기에 필요한 모든 필수적인 지식들을 제공할 것이다. 또한, 이 코스를 통해 GPU에 대한 Macro 수준의 세밀한 설계 구조와 동작을 이해하는 것을 토대로, 개발들이 자주 고민하는 것들에 대해 살펴볼 것이다. 즉, 어떻게 앱의 컨텐츠들이 내부 작업들로 전환되어 문제가 발생하는 지, 그리고 최종적으로 이런 문제를 Streamline에서 어떻게 발견해낼 것인지를 살펴볼 것이다.
추상 렌더링 머신(Abstract Rendering Machine)
엔지니어가 그래픽 성능에 대한 완벽한 분석을 위해 알아야 하는 거의 모든 필수적인 지식들은 ‘어떻게 OpenGL ES가 시스템 내부적으로 동작하는가?’ 를 이해하는 것이다.
개발자들은 GPU Driver H/W와 S/W를 포함하는 GPU 서브시스템에 관한 세부적인 구현을 알기 어려울 뿐더러 제어 할 수도 없으며, 사용 상에 있어서도 매우 제한적이다. 따라서, GPU 서브 시스템을 이해시키는 것을 피하면서도 렌더링에 대한 기본 동작을 쉽게 설명하기 위해, 간단한 추상 머신을 정의하는 것은 이해에 큰 도움이 된다. 추상 렌더링 머신은 각각 독립적인 세 가지의 파트로 나눌 수 있다.
* CPU-GPU 렌더링 파이프라인
* 타일 기반의 렌더링
* 쉐이더 코어 설계이번 첫 장에서는 첫 번째 내용인 “CPU-GPU 렌더링 파이프라인”을 다루어보도록 한다.
CPU-GPU 렌더링 파이프라인(CPU-GPU Rendering Pipeline)
동기화 API의 비동기화 처리 방식 (역자 - GLES API의 Draw Call Seq.는 환상이다.)
첫 번째로 알아야 하는 것은 앱의 ‘OpenGL ES API 호출들’과, ‘실제 렌더링 연산 실행에 필요한 것들’의 관계를 이해하는 것이다. 애플리케이션 관점에서는 OpenGL ES가 마치 동기화된 API인 것 처럼 보인다. 예를 들어, 애플리케이션에서는 상태를 설정하는 일련의 GL API 호출을 수행한 후, 마지막으로 glDraw*()을 통해 그리는 연산을 호출하게 된다. 이렇게 동기화를 전제로 한 호출들은 draw call이 끝나면 모든 것이 GPU에 의해 수행되어 그려졌을 것으로 가정한다. 그러나, 드라이버 동작 상의 관점에서는 이상적이고 마치 꿈만 같은 이야기이다. (역자 - 즉, 매 프레임마다 일련의 GL 호출들이 실제 gpu 내부에서는 순서대로 처리되지는 않는다는 것이다.)
이러한 관점에서, eglSwapBuffers()의 호출이 front-back 버퍼간 교체가 실제로 일어난다는 것은 논리적으로 사실이지만, 드라이버의 관점에서는 환상일 뿐이다. 그러나 대부분의 플랫폼에서는 실제 물리 메모리에 대한 swap은 더 나중에 일어나게 된다.
파이프라이닝(Pipelining) - CPU-GPU idle 최소화를 통한 성능 극대화
이러한 동기화에 대한 환상이 만들어지게 된 배경은 사실 성능때문이다. 만약 정말 동기화된 API였다면, 아래 그림처럼 매 순간의 렌더링 호출마다 GPU가 연산 중일 때에는 CPU가 idle 상태가 되고, 반대로 CPU가 처리하는 동안에는 GPU가 idle인 과정이 번갈하가며 발생해야 한다. 그렇지만, 이런 방식은 성능 최적화 면에서 매우 비효율적이고 납득할 수 없는 방식임은 분명하다.
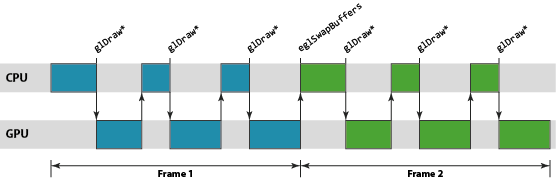
다행히도, 실제로는 CPU-GPU간의 이러한 idle time이 발생하지 않으며 실제 frame swap은 내부에서 비동기로 처리된다. 그렇지만, GLES API의 사용 상에 있어서는 마치 동기화된 draw call인 것처럼 보일 수 있도록 설계되었다. 또한 이러한 설계 덕분에, 어떤 한 workload (역자 - 프레임 하나를 그리기 위한 일련의 작업)가 실제 GPU 파이프라인 내에서 처리되고 있는 동안에도, CPU는 GPU에게 새로운 작업을 전달할 수 있는 것이다. 이를 통해, 파이프라인 내부를 아래와 같이 꽉 찬 상태로 유지할 수 있으며 최적의 GPU 성능을 발휘하는 것을 가능케 하고 있다.
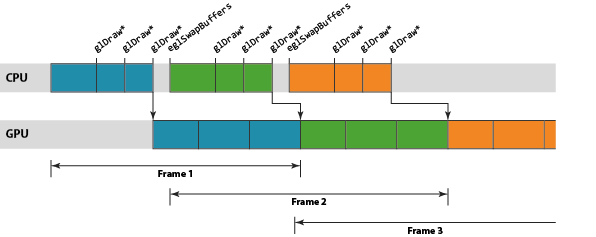
매 작업 단위(unit)들은 Mali GPU 파이프라인 내에서 각각 render target을 기준으로 스케줄링 된다. (역자-렌더 타겟은 보통 window surface나 offscreen- render buffer 등이 될 것이다.) 여기서 하나의 렌더 타겟은 두 단계로 처리된다.
* 해당 render target의 전체 vertex shading 처리
* 해당 render target의 전체 fragment shading 처리따라서, 위의 논리적인 렌더링 파이프라인은 아래의 3개의 스테이지로 다시 나누어 이해할 수 있다.
* CPU 처리
* 기하 처리(역자 - vertex 처리)
* fragment 처리
파이프라인 쓰로틀링(Pipeline Throttling) (역자 - GPU job 처리 지연을 위한 CPU 블로킹 기법)
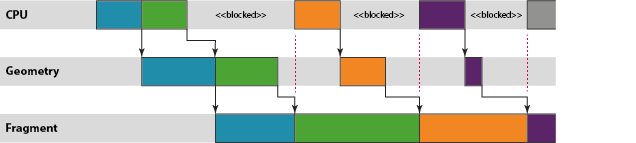
위 그림에서처럼 fragment 처리 단계에서 로드가 높은 경우가 대부분이며, CPU와 Geometry stage의 연산량을 훨씬 뛰어넘기 때문에 Lagging(버벅임)의 주 원인이 된다. 실제로 대부분의 앱은 vertices shading 보다 훨씬 더 많은 fragments shading 처리를 요구한다.
이러한 특성 때문에, 파이프라인이 꽉 찬 경우 밀린 프레임이 fragment stage에서 그려지는 동안, 의도적으로 CPU의 작업을 지연시키는 매커니즘은 필수적이다. (사용자의 터치 이벤트와 화면 UI 사이에 반응이 100ms 이상 차이가 발생하게 되면, 사용자는 불편함을 느낄 수 있다.) 따라서 fragment stage의 작업 대기 지연이 늘어나는 것을 방지하기 위해서, 파이프라인의 작업을 담는 backlog가 너무 커지지는 말아야 한다. 최고의 성능을 유지하는 한도 내에서만 CPU가 작업을 큐잉할 수 있도록, 주기적으로 CPU 쓰레드를 지연시키는 메커니즘이 필요하다.
이러한 쓰로틀링 메커니즘은 gpu driver가 지원하는 것이 아니라, 보통 Host windowing system에서 자체적으로 지원한다. 예를 들어, 안드로이드의 경우에는 모바일 화면을 사용자가 회전시키는 동안 gpu는 그 어떤 frame drawing 연산도 처리하지 못한다. 또한, 안드로이드의 windowing system manager 격인 SurfaceFlinger는 렌더링 할 버퍼의 큐가 일정 수 N을 초과하는 경우, 애플리케이션의 그래픽 스택에 버퍼를 다시 반환하는 방법을 통해 GPU 파이프라인을 제어한다.
따라서 이러한 상황이 실제로 발생하게 되면, N에 도달하여 CPU가 idle 상태가 되어있으리라 예상할 수 있는데, 이 과정은 곧 디스플레이 화면이 실제 버퍼를 소비(화면에 출력)하는 동안 CPU의 egl/gles 함수의 호출이 일시적으로 blocking될 것이다.
화면 주사율에 따른 디스플레이 화면의 업데이트 속도보다 GPU 버퍼가 더 자주 업데이트되는 경우에도, 이러한 blocking 동작을 통해 파이프라인 버퍼링을 제한시킨다. 바로 수직동기화(vsync)가 이 역할을 수행한다. vsync는 디스플레이 컨트롤러에게 완전히 그려진 next frame buffer를 내보내도 된다는 시그널을 일으키는 것이다. 만약, 화면 업데이트 속도보다 빠른 GPU 처리능력으로 인해, GPU가 이미 작업을 마친 버퍼들을 SurfaceFlinger가 실제 디스플레이 화면에 뿌리지 못하면, 마찬가지로 버퍼가 최대 N개만큼 될 때까지 쌓이게 될 것이다.
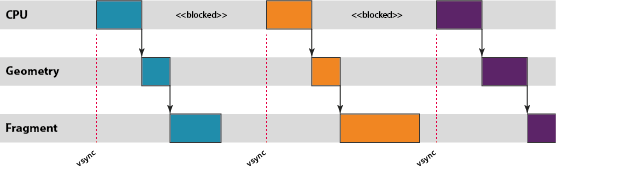
위 그림처럼, vsync가 발생하는 경우 CPU, GPU가 모두 해당 시간동안 idle 상태가 된다. 플랫폼에서의 DVFS(Dynamic Voltage Frequency Scaling)는 이러한 시나리오에서 동작 주파수를 낮추어 전압과 에너지 소모를 줄일 수 있도록 동작할 것이다. 그러나 DVFS의 주파수 제어 동작이 다소 이산적이기에, 어느 정도의 유휴 시간이 발생할 것이다.
요약
이번 장에서 외부적 관점에서는 동기화 GLES API이지만, 비동기화된 내부 처리 방식이라는 사실을 렌더링 파이프라인을 통해 알아보았다. 다음 절에서는 타일 기반 렌더링 방식으로 동작하는 Mali GPU의 관점에서의 추상 (렌더링) 머신에 대해 알아볼 것이다.
[NEXT] The Mali GPU - An Abstract Machine, Part 2 - Tile based rendering
출처 : https://community.arm.com/graphics/b/blog/posts/the-mali-gpu-an-abstract-machine-part-1---frame-pipelining 본 자료는 ARM Community의 Blog를 통해 공개된 내용을 한국어로 번역한 것입니다. 문의 : artrointel@gmail.com