· Woohyun Kim · Graphics · 13 min read
Mali GPU 추상 머신 2부 - 타일 기반 렌더링
타일 기반 렌더링 관점에서 Mali GPU의 동작과 메모리 효율을 설명합니다.
목차
The Mali GPU - An Abstract Machine, Part 1 - Frame Pipelining The Mali GPU - An Abstract Machine, Part 2 - Tile based rendering The Mali GPU - An Abstract Machine, Part 3 - The Midgard Shader Core
이전 장에서는 애플리케이션 관점에서의 GPU 드라이버 동작을 추상머신의 정의를 통해 설명하였다. 추상 머신은 개발자로 하여금 GLES API 호출이 애플리케이션의 성능에 어떤 영향을 미칠 것인지에 대한 동작을 설명하기 위한 것이다. 앞으로도 그래픽 성능에 줄만한 요인들을 설명하기 위해 추상 머신을 사용할 것이다.
이번 장에서는 Mali의 타일 기반 렌더링 모델의 관점에서 추상 머신을 설명하도록 할 것이다. 만약 이전 장을 읽지 않았다면 꼭 먼저 읽기를 바란다.
전통적 설계 방식 - 버퍼를 위한 주메모리 사용
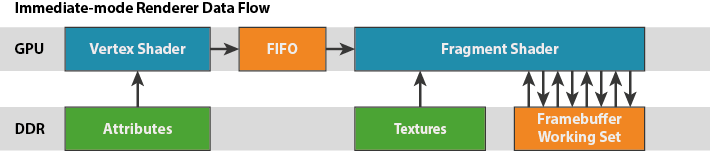
데스크탑 환경에서 보편적인 GPU 아키텍쳐(“즉시모드” 설계라 불리는 아키텍쳐)에서는 매 draw call에서 보여지는 모든 primitive (이하 도형) 에 대해 호출된 순서대로 fragment shader가 처리되었다. 즉, 각각의 도형들은 그 다음 도형이 그려지기 전에 완전히 그려졌다. 다시 말해, 다음과 같다.
foreach(primitive) // primitive 순서대로 fragment rendering을 온전히 수행한다.
foreach(fragment)
render fragment이러한 동작 메커니즘은, 스크린으로 렌더링되어야 하는 모든 triangle들의 data, 즉 working set이 유지된 상태로 수행되어야 하며, 따라서 요구되는 memory size가 매우 크다. full-screen 기준에서 볼 때 컬러버퍼와 깊이/스텐실 버퍼(24+8bit)가 반드시 포함되어야 하며, 이들 버퍼를 포함하는 working set은 보통 픽셀 당 32비트를 차지한다. 따라서 1080p (FHD)디스플레이의 경우 따라서 16MB (1080x1920 * 4 byte * 2 buffer)가 필요하며, 4k2k TV의 경우 64mb가 필요하다. 이렇듯, 높은 memory size를 요구하는 working buffers는 칩 외부인 DRAM에 저장된다.
Mali driver의 설계 - 버퍼를 위한 fast RAM(로컬 타일 메모리) 사용
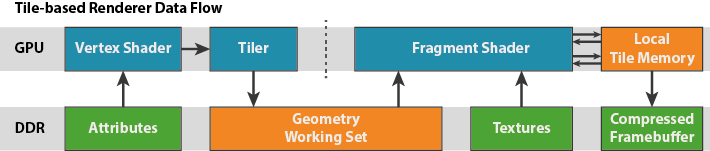
이와 달리, Mali는 타일 기반의 렌더링으로 널리 불리는 기법을 사용한다. 제한된 전력(에너지) 소비와 외부 memory 접근이 제한적인 상황에서 자주 사용되는 기법이다. 이전 블로그에서 설명한 바와 같이, 각 렌더 타겟에 대해 2-pass 렌더링(역자 - vertex job -> fragment job 순으로 처리)을 수행한다. 첫 번째 작업은 geometry stage(vertex)에서 스크린 하나를 16x16 pixel 사이즈의 타일 집합으로 쪼개는 것인데, 그 이후 렌더링 할 primitives의 정보가 포함된 타일의 리스트를 생성한다. 두 번째 작업은 fragment stage에서 각 쉐이더 코어가 한 개의 타일을 처리하는데, 한꺼번에 모든 프로세스들이 동시에 타일을 처리한다. 따라서 알고리즘은 대략 다음과 같다.
foreach(tile) // 각 쉐이더의 코어가 타일을 하나씩 처리
foreach(primitive in tile)
foreach(fragment in the primitive)
render fragment전체 스크린을 16x16 크기의 타일로 쪼개어진 것을 처리하기에, 각 타일의 작아진 working set(컬러,버퍼/스텐실 버퍼)은 GPU 쉐이더 코어에 물리적으로 근접한 fast RAM(Local Tile Memory)에 저장할 수 있다.
이러한 타일 기반의 설계방식은 많은 이점이 있기에, 아래와 같은 메모리 대역폭 비용에 대한 이해를 할 필요가 있다.
모든 working set에 대한 접근은 Local memory access이며, 따라서 저전력으로도 빠른 접근이 가능하다. 외부 DRAM에 대한 r/w를 수행하면서 높은 전력(대략 1GB/s의 대역폭 당 120mW를 소모)을 필요로 하는 전통적 설계와는 다른 점이며, 내부 메모리 접근 비용은 이보다 훨씬 적다. 따라서 위 사실은 매우 중요하다.
블렌딩 처리는 매우 빠르며 에너지 효율이 좋다. 블렌딩(컬러버퍼간 연산을 통한 합성) 방정식에서 필요로 하는 color data가 Local Tile Memory에 상주하여 항상 사용가능하기 때문이다.
실제로 4/8/16x MSAA을 처리할 수 있을 만큼의 샘플을 충분히 Local Memory에 적재할 수 있으며 그만큼 타일이 충분히 작다. 다시말해, 높은 배율의 MSAA 구현에 있어서 고효율적이다. 반면에 전통적 설계방식(즉시모드)에서는 외부 메모리에 대한 접근 비용이 매우 크기에 MSAA를 개발자가 선택할 수 있는 feature로서 제공되고 있다. (4k2k buffer의 경우 16x MSAA의 경우 1GB나 필요하다.)
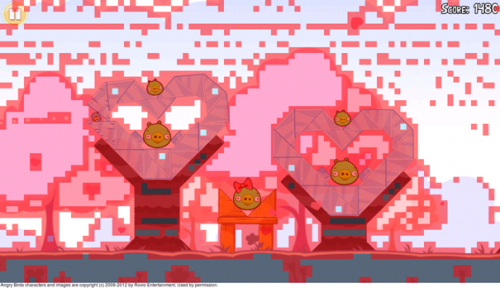
실제로 화면에 그려야 할 Color data를 가지는 타일 영역만 타일리스트에 등록되어 그려진다. CRC check(트랜잭션 제거) 기법을 통해 현재 컬러 데이터와의 비교를 통해 새롭게 그려져야 할 영역을 가지고 있는 타일만을 write함으로써 전력소모를 줄인다. 예를 들어, 아래와 같은 앵그리버드의 렌더링 예제에서 분홍색 부분의 Color data만 새롭게 write하게 되며, 나머지 영역은 모두 업데이트하지 않는다.
트랜잭션 제거 이후에도 남은 타일 데이터들을 타일의 Color data를 압축한다.(AFBC) 이는 메모리 대역폭과 전력 소모를 훨씬 더 줄이기 위함이다. offscreen FBO인 렌더 타겟에도 적용될 수 있다. 더불어 디스플레이 컨트롤러가 AFBC를 지원하는 경우, 서브렌더패스 등에서 텍스쳐 read-back이 가능하고 window surface에서도 사용이 가능하다.
깊이/스텐실 버퍼의 주메모리 상주가 필요없다 (- 역자) 대부분의 깊이/스텐실 버퍼는 프레임 렌더링이 완료된 이후로는 필요가 없어지는데, glDiscardFrameBufferExt (GLES 2.0) 혹은 glInvalidateFrameBuffer (GLES 3.0) 등을 호출하지 않는 한, 이 버퍼들은 사실 상 필요가 없으므로 Mali에서는 main memory에 write back 하지 않는다. 이는 대역폭과 전력소모 측면에 있어서 큰 이득이 된다.
저비용의 MSAA나, 프레임버퍼와 관련된 주요 데이터의 메모리 대역폭과 전류 소모의 사용량 감소를 통해 위와 같은 많은 장점을 가진것이 바로 타일 기반 렌더링이다.
반면, 타일 기반 렌더링의 단점은 vertex에서 fragment로의 job 핸드오버 과정에 있다. geometry stage에서 처리되어 생성되는 varying 데이터와 tile의 상태정보가 fragment로 넘겨지기 위해서는 주메모리(main memory)로 write 후, fragment stage에서 다시 read하여야 하는 점이다. 따라서, 주 메모리에 ‘varying 및 tile state 데이터 전달을 위해 주메모리 대역폭을 사용’할 것인지, 아니면 이러한 데이터 전달 과정을 최소화하는 방향이 더 효율적인지에 대한 성능 균형이 잘 이루어져야 할 것이다. (역자 - varying 및 tile data는 vshader에서의 처리결과이기에, vertex shader에서의 결과를 fragment shader로 전달받는 데이터가 많으면 주메모리 사용으로 인한 성능 드롭이 발생할 수 있다. )
시장에서는 점점 더 높은 해상도의 디스플레이로 확산되고 있다. 현재 스마트폰 시장에서는 FHD가 기본 해상도이며, Mali-T604이 탑재된 구글 넥서스 등의 태블릿의 경우 2560x1600을 사용하기도 한다. 특히 TV 시장에서는 4k2k 시대가 열리고 있다. 프레임 버퍼의 대역폭에 의존하는 스크린 해상도의 크기가 점점 넓어진다는 사실로 인해, Mali GPU는 앞으로도 더 좋은 성능을 발휘할 것이다.
복잡한 기하처리(vertex stage) 과정 또한 Mali GPU에서 잘 처리할 수 있는 기법이 있다. 많은 하이엔드급 벤치마크 프로그램에서는 고사양 게임에서보다 훨씬 더 많은 triangle을 그리기도 한다. 이로 인해 geometry data가 주메모리를 거치는 문제가 발생하지만, 이러한 문제를 해결할 수 있는 팁과 기법을 통해 GPU 성능 최적화가 가능하다.
이러한 기법은 매우 가치가 있기 때문에, 해당 시리즈의 후반부에서 소개할 것이다.
Summery
이번 장에서는 Mali GPU의 타일 기반 렌더링을 데스크탑 환경에서의 즉시모드 렌더러와 비교/대조하여, 메모리 대역폭을 중점적으로 설명하였다.
추상머신에 대한 정의는 이 것으로 마치며, 다음 장에서는 간단한 Mali Shader core를 구성하고 있는 block model에 대해 설명할 것이다. 다음 modle 과정에서의 유용한 내용을 토대로, Mali GPU에서의 애플리케이션 동작을 최적화하는데 사용할 수 있을 것이다.
[NEXT] The Mali GPU - An Abstract Machine, Part 3 - The Midgard Shader Core
출처 : https://community.arm.com/graphics/b/blog/posts/the-mali-gpu-an-abstract-machine-part-2---tile-based-rendering 본 자료는 ARM Community의 Blog를 통해 공개된 내용을 한국어로 번역한 것입니다. 문의 : artrointel@gmail.com