· Woohyun Kim · Graphics · 10 min read
Mali GPU 추상 머신 3부 - Midgard 셰이더 코어
Midgard 계열 Mali GPU의 프로그래머블 셰이더 코어 구조를 한국어로 정리합니다.
목차
The Mali GPU - An Abstract Machine, Part 2 - Tile based rendering The Mali GPU - An Abstract Machine, Part 3 - The Midgard Shader Core Mali Performance 1: Checking the Pipeline
이전 장에서는 Mali GPU를 통해 프레임 수준에서의 파이프라이닝, 그리고 타일 기반 렌더링 아키텍쳐에 대해 소개하였다. 앞서 설명하였던 그래픽스 스택의 이해를 통해, 애플리케이션에서 GPU 아키텍쳐 특성에 따라 성능 최적화를 할 수 있는 팁을 제공하였다.
이번 장에서는 추상 머신의 마지막 요소로서 범용적으로 쓰이는 Mali ‘Midgard’ GPU의 ‘프로그래밍 가능한 코어(Programmable Core)‘에 대한 정의를 마무리 지음으로써 추상 머신에 대한 설명을 마칠 것이다. 이전 장을 읽지 않았다면 반드시 읽기를 바란다.
GPU Architecture
Midgard 계열의 GPU(Mali-T600, Mali-T700, Mali-T800 시리즈)는 범용 목적의 쉐이더 코어 설계를 사용하고 있다. 다시 말해, H/W 설계 상 단일의 쉐이더 코어가 다수 탑재되어 있다는 것을 말한다. 이 단일코어는 vertex, fragment, compute shader 등 모든 타입의 쉐이더 코드들을 처리할 수 있다.
쉐이더 코어의 수는 특정 칩 제조사(chipset vendor)에 의해 결정되며, 따라서 칩 제조사가 성능Spec이나 칩 H/W 제약 등에 따라 탑재할 쉐이더 코어 수를 결정할 수 있다. 예로는 Mali-T760은 쉐이더 코어의 수가 1~16개이며 일반적으로 4개 혹은 8개의 코어를 가지고 있다.
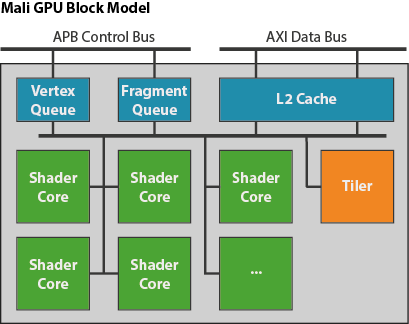
한 렌더타겟으로인해 발생하는 그래픽 처리를 위한 하나의 작업(이하 workload)은 각각 적합한 쌍의 큐로 적재되는데, 하나는 vertex/tiling workload 큐이며 다른 하나는 fragment workload 큐로서 한 쌍을 이룬다. 물론 각각의 두 큐로 큐잉된 workload들은 GPU에서 병렬 처리된다. 다시 말해, 서로다른 렌더타겟의 vertex와 fragment 처리는 파이프라이닝 되어 병렬처리된다. (첫 번째 블로그 참조) 또한 한 렌더타겟을 위한 workload는 작은 단위로 쪼개어져 각 쉐이더코어로 분산되어 처리되거나, 타일링 workload의 경우 이미 정해진 크기의 tiling unit으로 쪼개어진다. (두 번째 블로그 참조)
쉐이더 코어는 성능을 위해 L1캐쉬를 공유하게 되며, 이는 반복된 data fetch로 인한 메모리 대역폭을 줄이는 데에도 기여한다. 코어의 수처럼, L2캐쉬의 크기 또한 chipset vendor가 결정한다. 보통 32~64KB가 채택되며 물리적인 공간제약에 따라 바뀔 수 있다. 해당 캐쉬와 외부 메모리에 연결되는 메모리 버스 대역과 포트의 수 또한 모두 chipset vendor가 결정한다. 그러나 코어 클럭당 32비트 픽셀을 write할수 있도록 설계하기 때문에, 8 코어 디자인에 256비트의 메모리 대역폭을 사용하는 것이 합리적일 것이다.
The Midgard Shader Core - 코어는 다수의 프로그래밍 가능한 HW Block(tripipe)들로 구성되어 있다.
Mali의 쉐이더 코어는 다수의 tripipe라는 고정된 기능을 하는 Hardware block인 실행코어의 집단으로 구성되어 있다. 고정된 기능을 가진 tripipe의 집단은 쉐이더 연산 (래스터화, 깊이테스트, 블렌딩과 같은 쉐이딩 전처리, 최종 렌더링에 필요한 타일 데이터 쓰기 등)에 필요한 셋업을 수행한다. 즉, tripipe는 쉐이더 프로그램을 처리할 의무를 가진, 프로그래밍이 가능한 작은 단위의 하드웨어 모듈이 되는 것이다.
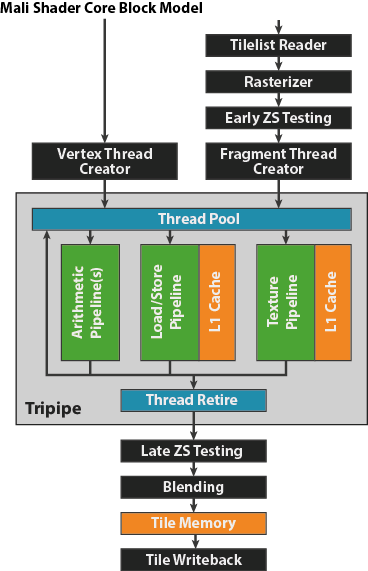
The Tripipe
tripipe 설계는 위 그림처럼 세가지 종류의 실행 파이프라인이 존재하며 각각 산술연산처리, 메모리 적재/저장과 varying 접근 제어, 텍스쳐 접근 제어를 수행한다. 쉐이더 코어 당 적재/저장과 텍스쳐 파이프는 각각 하나씩 존재하나, 요즘에는 chipset vendor에서 산술연산 파이프를 2개 사용하는 경우가 많은 편이며 Mali-T880은 3개를 가지고 있다.
대규모 멀티쓰레드 환경
코어 당 하나의 쓰레드로 수행되는 전통적인 CPU 아키텍쳐와 달리, tripipe는 멀티쓰레드 처리 엔진이다. 수 백개의 하드웨어 쓰레드들이 tripipe 내에서 동시에 실행되며, 각각 쉐이딩 된 하나의 vertex 혹은 fragment마다 쓰레드가 생성되는 것이다. 이렇게 많은 수의 쓰레드들은 메모리 지연을 숨기기 위해 존재하는데, 다수의 쓰레드가 메모리 대기로 인해 멈추더라도, 최소 하나 이상의 쓰레드가 정상 동작하는 한 효율적인 처리가 가능하다. (역자 - 다수의 하드웨어 쓰레드로 구성되어 있기에, 쓰레드들이 임의의 메모리 접근 시 최대한의 H/W 대역폭으로 동작할 수 있다는 뜻으로 이해하였다.)
산술 파이프라인 : 벡터 코어
산술 파이프라인(줄여서 A-pipe)는 SIMD(Single Instruction Multiple Data) 벡터 처리 엔진으로, 4쌍의 128비트 워드를 가진 레지스터를 탑재한 산술 unit들로 이루어져있다. 따라서 이 레지스터는 2FP64(64Bit of Floating Point), 4FP32, 8FP16, 2Int64, … 등으로 유연하게 접근할 수 있다. 즉, 한 번의 연산으로 8개의 mediump values (8*FP16)를 처리할 수 있다는 것이며, OpenCL Kernel의 경우 8비트 luminance data인 픽셀의 16개를 한 Cycle에 처리할 수 있다는 것이다.
텍스쳐 파이프라인
텍스쳐 파이프라인(줄여서 T-pipe)은 텍스쳐 메모리 접근에 대한 모든 책임을 가지고 있다. 텍스쳐 파이프라인은 한 클럭 당 brilinear 필터링된 텍셀을 반환할 수 있으며, trilinear 필터링은 서로다른 두개의 밉맵을 메모리로부터 로드해야하므로, 작업을 완료하기까지 2 Cycle을 필요로 한다.
로드/적재 파이프라인
로드/적재 파이프라인(LS-pipe)은 텍스쳐 메모리를 제외한 나머지 모든 쉐이더 메모리 접근에 대한 책임을 가지고 있다.
그래픽 workload의 관점에서 생각해보면 하나의 Vertex의 Attribute 읽기, 그리고 해당 Vertex 쉐이딩 처리 이후 생성된 vertex output의 쓰기, fragment 쉐이딩 단계에서 이러한 varying value 읽기가 여기에 속한다.
일반적으로 모든 명령어는 단일 메모리 접근 연산이며, 산술 파이프라인과 마찬가지로 벡터 연산이므로 highp vec4 varying(4*32bit)을 1 Cycle로 로드할 수 있다.
(번역 중)
[NEXT] Mali Performance 1: Checking the Pipeline
출처 : https://community.arm.com/graphics/b/blog/posts/mali-performance-1-checking-the-pipeline 본 자료는 ARM Community의 Blog를 통해 공개된 내용을 한국어로 번역한 것입니다. 문의 : artrointel@gmail.com